웹에서 대용량 파일을 다운로드하는 다양한 방법
어느 날, 스톡영상이 다운로드 되지 않는다는 cs가 들어왔다.
유저가 다운로드 한 파일을 확인해보니 1분이 넘는 길이에 4k 화질로 용량이 꽤 큰 편이였다.
기존 다운로드 방식은 아래와 같았다.
const response = await fetch('file-url');
const reader = response.body.getReader();
let chunks = [];
let receivedLength = 0;
while(true) {
const {done, value} = await reader.read();
if (done) break;
chunks.push(value); // Chunk들을 배열에 누적
receivedLength += value.length; // 누적된 길이 계산
}
// 누적된 chunks를 합쳐서 파일로 처리
let blob = new Blob(chunks);원인은 기존 다운로드가 Blob 형태였는데, Blob은 InMemory 방식이라, 파일 크기가 메모리(RAM)보다 큰 경우 예외 상황이 발생하는 것이였다.
동료가 리서치한 3가지 정도 방안이 있었는데,
- Stream 처리
- multipart download > s3 using large file scenario docs
- window showSaveFilePicker
2번의 경우 object의 정확한 디렉토리 위치를 전달하는 방식이 필요했는데, 현재 사용하는 url이 보안을 추구하는 preSignedUrl이라 맞지않았고 3번의 경우 safari는 미지원하기 때문에 1번 Stream 방식으로 처리하기로 결정했다.
다만 브라우저 native의 stream은 제약이 많은데, 우선순위가 높은 해당 이슈를 개선하기엔 패키지를 사용하는게 합리적이라 판단되어 FileSaver를 extends한 streamsaver를 사용하기로 했다.
마지막 업데이트가 2-3년 전이라는게 캥기긴 했지만 star를 많이 받았고 관련 내용도 많아서 타협하기로 했다
Streamsaver#
패키지 설치 후 대략 아래와 같이 작업해서 fetch할 url과 filename을 전달받는 hook을 구현해서 다운로드 하는곳에 연결하였다.
import {createWriteStream} from 'streamsaver'
// ...
const res = await fetch(url, { signal: abortController.current.signal });
const readableStream = res.body;
const fileStream = createWriteStream(filename);
// ...
if (window.WritableStream) {
return readableStream
.pipeThrough(progress, { signal: abortController.current?.signal })
.pipeTo(fileStream, { signal: abortController.current?.signal })
.then(() => {
setStatus('done');
onSuccess?.();
})
.catch((err) => {
onError?.(err);
setStatus('error');
});
}
const writer = fileStream.getWriter();
const reader = res.body?.getReader();
const pump = () => {
reader
?.read()
.then((res) => (res.done ? writer.close() : writer.write(res.value).then(pump)))
.catch((err) => {
onError?.(err);
setStatus('error');
});
};
pump();
문제가 없었다. 정상 동작했었다
문제가 없었다고 생각했는데, 사파리에선 동작하지 않았다.
폴리필이 문제일까 생각해서 구글링한대로 web-streams-polyfill도 설치해봤다.
그러나 동작하지 않았다.
결국엔 패키지에 문제가 있다고 판단 (2년넘게 업데이트가 되지 않았기 때문..?) 하여 패키지 없이 직접 구현해보기로 했다.
Stream Api를 찾아보고 여러 시행착오 끝에 reader와 writer / pipeThrough와 pipeTo에 대해 점점 이해가 됐다.
const response = await fetch('file-url');
const reader = response.body.getReader();
const stream = new WritableStream({
write(chunk) {
// 각 chunk를 실시간으로 저장하거나 다운로드 처리processChunk(chunk); // 예시 함수로 실시간으로 처리
}
});
response.body.pipeTo(stream);그러나 이 또한 write(chunk) 를 하고 난 다음 어떻게 해야할 지 알수가 없었다.
구글링도 gpt도 해보니 패키지 없이 클라이언트단에서만 Stream 다운로드를 구현하기는 어렵고 Service Worker나 node(서버)를 같이 사용해야 한다고 했다.
우선 next.js를 사용하니 서버를 활용하기로 했다. app router에 맞게 수정을 했는데, 이 방법도 stream 형식으로 다운로드 할 수는 없었다.
이러한 여러 참고자료를 보다가 stream api 관련 보다는 large file을 어떻게 웹에서 다운로드 하는지를 찾아봤는데,
upload-and-download-files-using-presigned-urls 을 발견했다.
Presigned URLs#
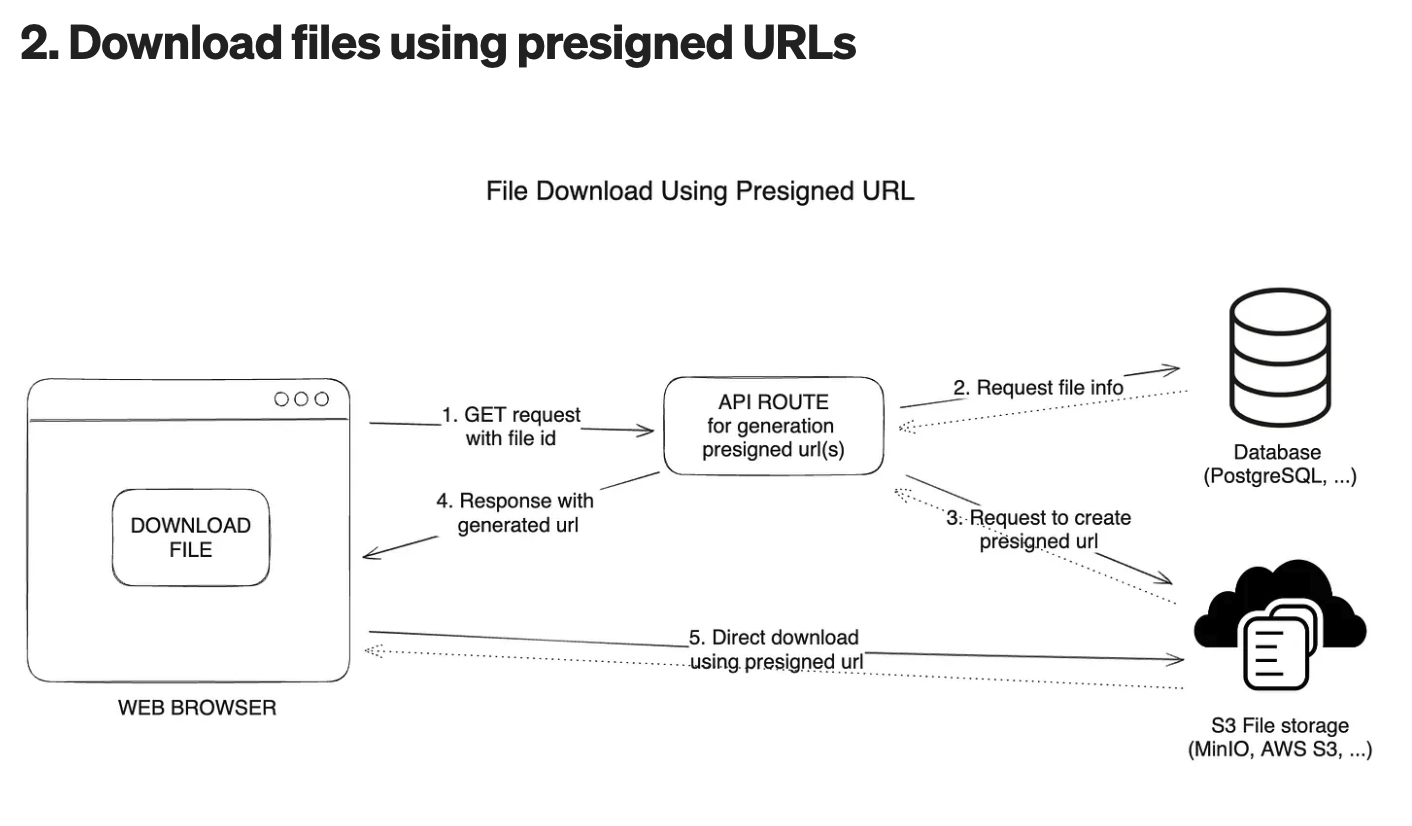
s3 > presigned URL을 사용해서 다운로드 할 수 있다는 내용을 찾게되었다.
presigned URL이란 말 그대로 미리 서명한 url이란 뜻으로 미리 일정시간동안 권한이나 옵션을 부여한 url이다
우리는 기존에 presignedUrl을 사용중이였고 window.open(presignedUrl,'_self') 를 실행하니 생각한대로의 분할 다운로드가 동작했다!!
그러나 mov 파일은 다운로드가 잘 됐는데, mp4파일은 새탭으로 열리는 문제가 있었다.
관련해서 찾아보니
기본 MIME 타입 처리 방식 때문일 수 있습니다. 브라우저는 확장자에 따라 파일을 어떻게 처리할지 결정하는데, .mp4는 대부분의 브라우저에서 재생 가능한 형식으로 간주되어 새 탭에서 열리지만, .mov 파일은 기본적으로 미디어 플레이어로 연동되거나 다운로드됩니다. 이 문제를 해결하기 위한 방법으로, 서버에서 제공하는 파일의 Content-Disposition 헤더를 설정할 수 있습니다.
라고 나와서 nextjs 로 구현된 서버를 까보니 presigned URL을 생성하는 로직이 있었는데 Content-Disposition 이 설정되어 있지 않았다.
async createGetPresignedUrl(
// ...args
): Promise<string> {
const command = new GetObjectCommand({
Bucket: this.AWS_BUCKET,
// ...
ResponseContentDisposition:`attachment;filename="${filename}"`,
})
// ...
}다음과 같이 ResponseContentDisposition를 설정하여 url을 생성하니 mp4파일도 정상적으로 다운로드가 됐다!!
그런데,#
검증과정에서 예기치 못한 이슈를 발견했는데, 한글이 포함된 filename의 경우 입력한 값이 아닌 디코딩된 이름으로 다운로드가 됐다.
그래서 encodeURI를 처리하였다. 프론트나 백에서 인코딩을 처리해주면 된다.
async createGetPresignedUrl(
// ...args
): Promise<string> {
const encodedFilename = encodeURI(filename);
const command = new GetObjectCommand({
Bucket: this.AWS_BUCKET,
// ...
ResponseContentDisposition:`attachment;filename="${encodedFilename}"`,
})
// ...
}운영중인 스톡 서비스는 사파리도 지원했는데, Header value cannot be represented using ISO-8859-1 라는 오류가 발생하면서 정상적으로 파일 다운로드가 되지않았다. 🤬
gpt에게 물어보니 친절하게 답을 알려주었다.
"Header value cannot be represented using ISO-8859-1"라는 에러는 HTTP 헤더에서 사용된 값이 ISO-8859-1 문자 인코딩으로 표현될 수 없을 때 발생합니다. ISO-8859-1은 대부분의 서구 언어에서 사용되는 8비트 문자 인코딩이지만, 한글이나 다른 비서구권 문자들(예: 일본어, 중국어) 또는 이모지와 같은 특수 문자는 이 인코딩으로 표현할 수 없습니다.
그래서 최종적으로 presignedUrl를 발급받는 코드가 완성됐다.
async function getPresignedUrl(bucketName, objectKey) {
// 파일명을 URI 인코딩 (UTF-8로 인코딩)
const filename = 'DropshotStock_UP6WFW1U_안경을 끼고 클립보드에 무언가를 적는 긴 머리 여성_preview.mov';
const encodedFilename = encodeURIComponent(filename);
const command = new GetObjectCommand({
Bucket: bucketName,
Key: objectKey,
ResponseContentDisposition: `attachment; filename*=UTF-8''${encodedFilename}`, // filename*을 사용하여 UTF-8 인코딩된 파일명 설정
});
try {
const presignedUrl = await getSignedUrl(s3Client, command, { expiresIn: 3600 });
return presignedUrl;
} catch (err) {
//...
}
}여러 시행착오가 있었지만, 삽질하는 과정에서 stream api에 대해서도 알게되었고, s3의 presigned URL도 학습할 기회가 있었다.